Filtering and forking¶
Filtering is an essential step in data process. Filtering let the user pick the data he exactly wants to pipe them into the rest of the process.
Nasca has this concept of filtering. A filter integrates seamlessly into the data flow, at any step of the flow.
Filters can be cumulated or not, and several filters can be invoked anywhere along the pipeline.
- Filtering
- As expected, filtering applies a bunch of rules (or filter) to keep matching data only.
- Forking
- Forking is a complement to filtering. When forking is invocated, the current pipeline is forked into two pipes: True and False The True pipe will carry the filtered data (as a basic filter would have done) whereas the False pipe will carry its complement.
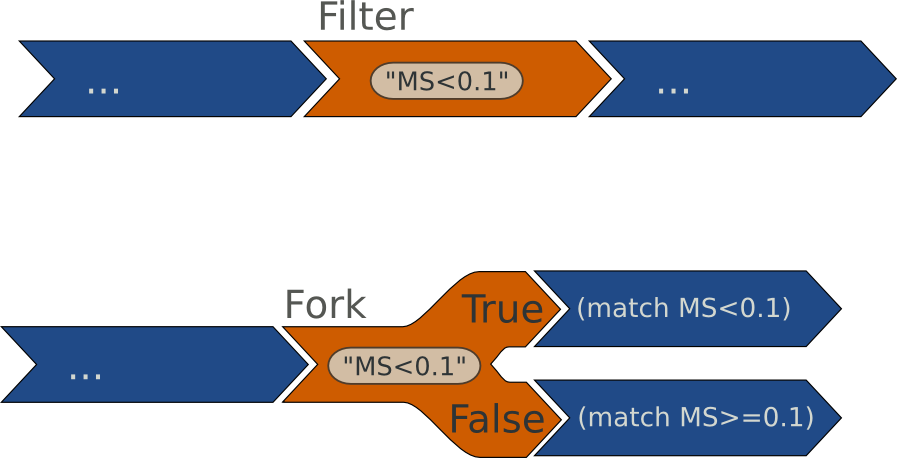
Nasca’s filtering and forking concepts
Filtering¶
A filtering operation is called from a pipeline via an IF(<rules>)(<True pipe>) statemant.
Let’s check a dummy case. Imagine a user that wish to apply a special analyst to bulkheads panels only. Assuming that those panels have already been tagged with “bulkhead” tag, filtering is as easy as:
C(panels) | IF(TAG~="bulkhead") ( <True pipe> ) [| <...>]
Where <...> is the rest of the process , and [| <...>] and optional trailing pipeline.
Now, if this user wishes to restrict the data to bulkhead panels whose thickness are less or equal to 0.75”:
C(panels) | IF(TAG~="bulkhead" && THK<=0.75) ( <True pipe> )
Last example now. Suppose that for any reason, Panel ID 7 was not tagged as a bulkhead, but our engineer wishes to process it with the others panels:
C(panels) | IF((TAG~="bulkhead" && THK<=0.75) || NID==7) ( <True pipe> )
where NID stands for Nasca ID (by opposition to EID (element ID)).
Forking¶
Create a fork consist in adding a “False pipe”:
C(panels) | IF(TAG~="bulkhead") ( <True pipe> ) ( <False pipe ) [| <...>]
Specifying a criterium¶
A filter rule is a combination of criteria. A citerium is always following the basic pattern: <key> <comparison operator> <value>
For example, to keep failing elements only, just insert the following filter:
<...> | IF(MS<0) | <...>
Obviously, this needs to take place after a MS is calculated, thus after an analyst, even if it is not mandatory to insert it right after and analyst.
You can figure the data flow as a paquet of data transiting through a pipe. Each paquet can be figured as a 2D table (like a spreadsheet) with rows and columns. Each column has one header and this header is a possible key.
Some keys are common to all data flow, wherever they come from (panels collector, bulkhead fittings, etc.). Among them:
- NID
- Nasca ID: This integer is unique among one group. One and only one panel has ID7, whereas several items may have the same NID: Bulkhead Fitting, joint, etc.
- EID
- Element ID
- PID
- Property ID: This integer is the same as the Property ID used for the FEA.
- MID
- Material ID: same value as the FEM.
etc.
Depending on the Collector or the Analysts implied in the pipline, some special keys may appear. Please refer to plugins specific manuals for more info.
In case a non-relevant key is specified, Nasca will terminate with a clear error message specifying which key was not relevant.
Tip
keys are not case-sensitive. Writing MS<0.2 will be interpreted in the same way as ms<0.2.
The comparison operator is one of (==, !=, <, <=, >, >=, ~=). They should all be self-explained, except the last one “~=”.
This latter means “is part of”. For example TAG=="bulkhead" will match all the panels tagged and only tagged with “bulkhead”.
You are probably more intersted by looking panels who are tagged as “bulkhead” among other tags. This is why the operator ~= exists! TAG~="bulkhead" will match any panel tagged with bulkhead whatever their other tags are.
Combining one or more criteria¶
criteria can be combined via two combination operators: && and ||.
- &&
- AND operator. Two criteria combined with the && operator will be restricted to the intersection of the two results. e.g. TAG~="bulkhead" && THK<=0.75 will pipe panels tagged as “bulkhead” AND, in the same time, having a thickness less or equal to 0.75”.
- ||
- OR operator. Two criteria combined with the || operator will be the union of the two results. e.g. TAG~="bulkhead" || THK<=0.75 will pipe panels tagged as “bulkhead” OR all the panels whose thickness is less or equal to 0.75”.
Danger
None of the combining operators has any kind of priority. The rule is to read from left to right:
``A && B || C``
will pobably give a different result than:
``A || C && B``.
Tip
It is strongly advised to use brackets to avoid any ambiguity:
A && (B || C)
is strictly equivalent to:
(B || C) && A
![]()
Table Of Contents
Related Topics
- Documentation overview
- Previous: Features and limitations
- Next: Supported plugins